
GenAI has grabbed many headlines lately, though the tech is not monolithic. There are different types of frameworks and sub technologies that fall under the GenAI umbrella, with some being more impactful than others, argues Moh Noori, CEO and founder of ScriptChain Health.
Currently, some of the most impactful use cases of generative artificial intelligence (GenAI) involve creating knowledge databases so that natural language interfaces have access to them. The purpose of this is to help working professionals in different industries find solutions to questions they may have. GenAI models face obstacles, however, not the least of which is the fact that they are often time consuming and costly due to the billions of parameters associated with them. With GenAI models, one must ensure that they are performing at their peak and consider the two main methods for building out their architecture – domain-specific fine tuning and retrieval augmented generation (RAG).
A group of researchers may have come up with a much better approach. The team developed a framework called retrieval augmented fine tuning (RAFT), a method that produces more effective results than either RAG or fine tuning that is only domain-specific. To test out their theory, the team of researchers used Microsoft Studio and an open source LLM called Llama 2 for their cloud computing. Readers who would like to check out the github repo on how the framework was built may refer to this link to the repository.
The RAFT method
In traditional RAG, when a query is presented to a model it fetches several documents from an index that are likely to contain relevant information. These documents serve as the context for generating an answer to the user’s query.
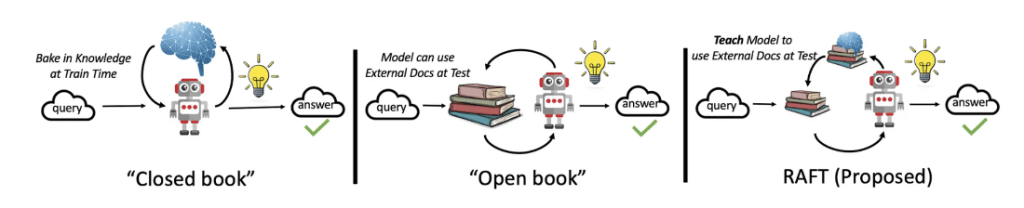
Fine-tuning allows the model to respond akin to a student in a closed-book exam. By contrast, RAG operates more like an open-book exam where the student has access to a textbook, facilitating easier answers due to the broader availability of information.
Both methods have significant drawbacks, however. Fine-tuning confines a model to its training data, leading to potential inaccuracies and fabrications. As for RAG, while grounded in retrieved documents, it may also include irrelevant documents due to semantic proximity.

To address RAG’s limitations, the research team that came up with RAFT proposed a solution inspired by students preparing for open book exams. RAFT prepares a model by familiarizing it with relevant documents beforehand. This approach involves creating a synthetic dataset with questions, associated documents – both relevant and irrelevant – generated answers, and explanatory passages. By fine-tuning models like Meta Llama 2 7B using this data, RAFT enhances a model’s adaptation to specific domains and improves the accuracy of answers derived from retrieved contexts. One ought to try the framework using a smaller LLM to lower the training and inference times. This enables one to measure and see how effective a model can be without exposing it to overfitting. The Llama 2 model is also a good baseline model that has lower latency inferences, making it a good model for A100 graphics processing units (GPUs) that can sit on a single GPU.
In conclusion, as a rule of thumb the RAFT method is usually the better choice when dealing with more specific domains as opposed to a generalized universal domain. RAG does, however, remain the more effective approach for more general questions, though it also implies a larger model to be fine-tuned. In short, for the time being there is always a tradeoff between accuracy and generalizability, though given GenAI’s fast-evolving nature it is likely only a matter of time until even more effective models and methodologies emerge.
References and further reading
- Medium – Advanced RAG 06: Exploring Query Rewriting
- Meta AI – RAFT: Sailing Llama towards better domain-specific RAG
- Cloud Atlas – How to improve RAG performance — Advanced RAG Patterns
- Microsoft Tech Community – RAFT (Retrieval Augmented Fine-tuning): A new way to teach LLMs to be better at RAG
- RAFT and its applications
